캐시(Cache)란?
자주 사용하는 데이터를 더 빠른 저장소(Redis 등)에 임시로 저장해 재사용하는 것이다.
DB나 외부 API 호출 없이 메모리에서 즉시 응답 가능하다.
왜 캐시를 보조로 사용하고 DB에는 원본을 저장할까?
캐시는 임시 저장소라서 데이터가 사라질 수 있고, 모든 데이터를 다 저장하기엔 메모리 비용이 크기 때문이다.
그리고 정확한 원본 데이터 저장은 DB가 더 잘하기 때문에,
캐시는 주로 자주 사용하는 일부 데이터만 빠르게 꺼내기 위해 보조로 사용한다.
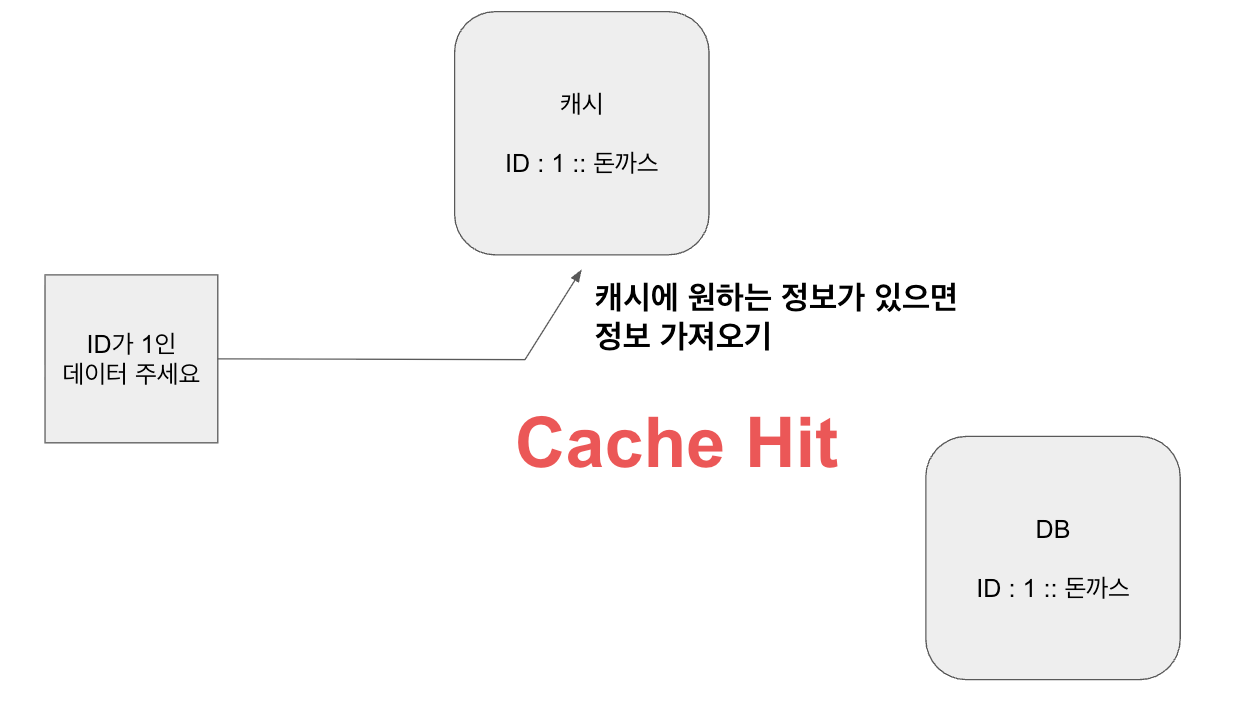
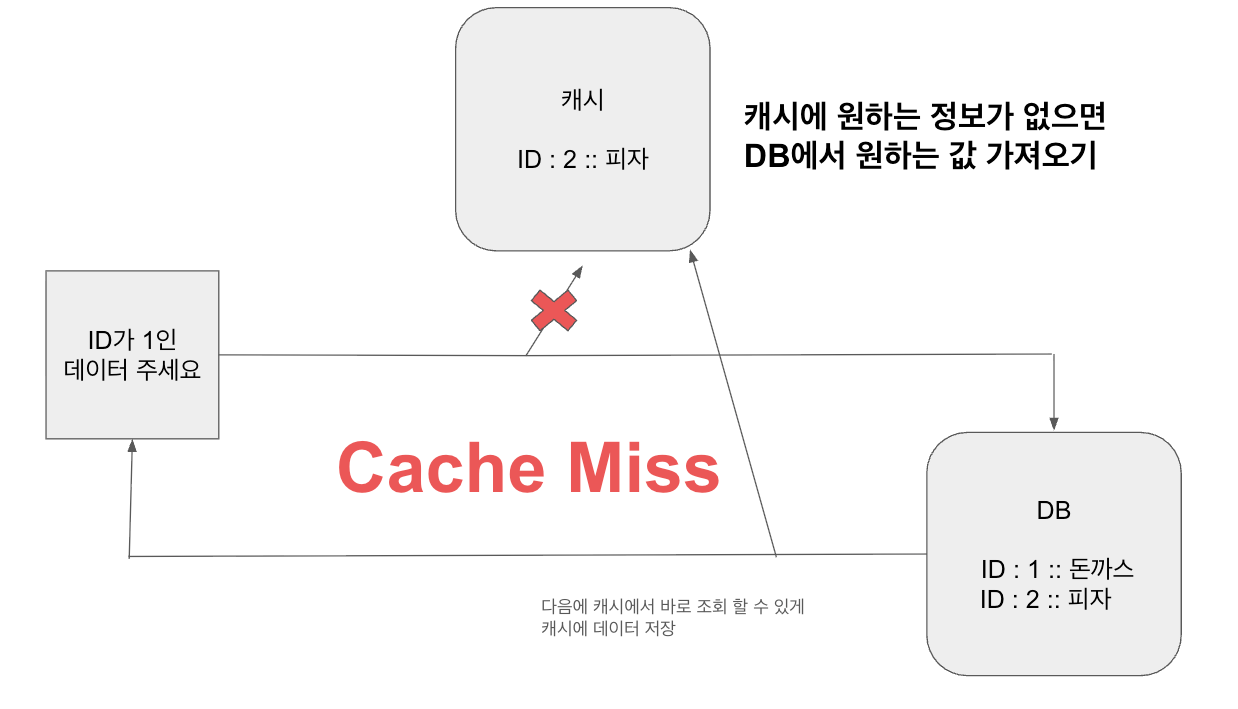
캐싱의 필요성
| 문제 | 캐시 도입 후 효과 |
| 반복적인 DB 조회 | ✅ 캐시로 응답 속도 10~100배 향상 |
| 외부 API 호출 지연 | ✅ API 응답 캐시로 비용 절감 |
| 트래픽 폭증 시 서버 부하 | ✅ 캐시로 병목 완화 |
| 인기 게시글/상품 조회 | ✅ 캐시로 빠른 응답 제공 |
캐시의 유형
| 구분 | 설명 | 예시 |
| 로컬 캐시(Local Cache) | 애플리케이션 내부 메모리에 저장 | ConcurrentHashMap, Caffeine |
| 분산 캐시(Distributed Cache) | 외부 서버에 저장해 여러 인스턴스가 공유 | Redis, Memcached |
캐시 전략
| 전략 | 설명 | 특징 |
| Write-through | DB에 쓰는 동시에 캐시도 갱신 | 데이터 일관성 ↑ |
| Write-back | 캐시에 먼저 쓰고, 나중에 DB 반영 | 속도 ↑, 위험도 ↑ |
| Cache-aside (Lazy Loading) | 요청 시 캐시 확인 → 없으면 DB 조회 후 캐시 저장 | 가장 일반적 |
| Cache Invalidation | 데이터 변경 시 캐시 삭제 또는 갱신 | 일관성 유지 핵심 |
'💻 Backend > 이론 및 실습' 카테고리의 다른 글
| 복합 인덱스 (0) | 2026.03.31 |
|---|---|
| Index (0) | 2026.03.31 |
| QueryDSL 검색 기능 구현 (0) | 2026.03.30 |
| QueryDSL 개념 및 적용 (0) | 2026.03.30 |
| VPC EC2 생성 (0) | 2026.03.10 |